در زبان انگلیسی، واژهی web برای اشاره به شبکهی ابریشمین تارهای تنیدهشده توسط عنکبوت
(spider web) به کار میرود. این واژه در حوزههای تخصصی مختلف نیز برای اشاره به مفاهیمی
به کار میرود که همگی از همین مفهوم عمومی استخراج شدهاند و بیانگر نوعی اتصال و
شبکهبندی هستند. برای نمونه، اصطلاح web در صنعت چاپ برای اشاره به یک روش چاپ افست به کار
میرود که در آن بهجای کاغذهای مجزا، رولهای پیوستهی کاغذ را در دستگاه چاپ قرار
میدهند. مهندسین عمران از این واژه برای اشاره به تیرهای داخلی یک خرپا استفاده میکنند.
در ریاضیات نیز واژهی web برای اشاره به یک مفهوم مرتبط با هندسه ریمانی استفاده میشود که
چیزی معادل یک grid است (مجموعهای از خطوط متقاطع که از برخورد آنها، مستطیلهایی ایجاد
میشود). دنیای کامپیوتر و فناوری اطلاعات نیز از این قاعده مستثنی نیست و web در این حوزه
هم مفهومی دارد که از روی شبکهی تارهای عنکبوتی گرفته شده و بیانگر اتصال شبکهمانند
اسنادی است که از طریق اینترنت در دسترس قرار میگیرند. در واقع، Web یا به عبارت دقیقتر
World Wide Web نامی است که به یک سرویس اطلاعاتی اطلاق میشود که از مجموعهای از اسناد
بههمپیوسته تشکیل میشود که روی شبکهی اینترنت و از طریق یک روش مبتنی بر درخواستو پاسخ
(request and response) در دسترس قرار دارند. در این درس، مروری خواهیم داشت بر تاریخچهی
سرویس وب و با اجزای تشکیلدهندهی این سرویس و نحوهی عملکرد آن آشنا میشویم.
تاریخچه ی مختصر وب
بسیاری از علوم و تکنولوژیهایی که در دورههای مختلفی از تاریخ ظهور کردهاند، با گذشت زمان
و با یک سرعت معقول، به سمت جاافتادن و همهگیر شدن حرکت کردهاند. اما در اغلب موارد،
اتفاقاتی رخ داده که برای این فرایند، حکم کاتالیزور را داشته و جریان رواج یک علم یا
تکنولوژی جدید را تسریع کرده است. به عنوان یک نمونه، اجازه دهید نحوهی پیدایش و ترویج
پژوهش عملیاتی (Operation Research) یا OR را مرور کنیم.
در سال 1941 و در خلال جنگ جهانی دوم، دانشمندان انگلیسی رادار را اختراع کردند اما ارتش
این کشور با نحوهی استفادهی بهینه از این وسیلهی جدید آشنا نبود. علاوه بر این، مسائلی
برای فرماندهان انگلیسی پیش آمده بود که نیاز به تصمیمگیری بهینه داشت. برای نمونه، یکی از
مسائل مورد بحث، این بود که بمبهایی که بمبافکنهای آنها به قصد انهدام زیردریاییهای
آلمانی رها میکنند، باید در چه عمقی از دریا منفجر شوند تا بیشترین خسارت را به
زیردریاییها وارد کنند. برای حل این مشکلات و یافتن جواب بهینه برای این قبیل سؤالات،
گروهی از دانشمندان گرد هم آمده و با بهکارگیری تکنیکهای مؤثر ریاضی و تحلیل دادههای
عملیاتی، تصمیماتی را اتخاذ کردند که در مجموع، باعث افزایش حدوداً ده برابری قدرت جنگی
انگلستان شد. برای نمونه، یک گروه از این دانشمندان که تحت سرپرستی فیزیکدانی به نام
Blackett فعالیت میکردند، در پیروزی انگلستان در جنگ دریایی آتلانتیک شمالی، نقش چشمگیری
داشتند. این دستاوردها باعث شد تا گروههای مشابهی نیز در ارتش امریکا ایجاد شود. به طور
کلی، فعالیتهای این گروهها که از آنها با نام گروههای پژوهش عملیاتی (operation
research) یا OR نام برده میشد، از مهمترین دلایل پیروزی متفقین در این جنگ خانمانسوز
بود. بعد از جنگ، استفاده از تکنیکهای OR که به طور کلی به «بهینهسازی» مربوط میشدند، در
صنایع نظامی ادامه پیدا کرد اما فواید این متدولوژی در صنایع غیرنظامی چندان مورد توجه قرار
نگرفت. البته این اتفاقی بود که به مرور زمان قطعاً رخ میداد اما دو اتفاق مهم باعث تسریع
فرایند ورود OR به صنایع غیرنظامی شد: یکی تولید کامپیوترهای الکترونیک که قادر بودند
محاسبات را با سرعت بسیار بالا انجام دهند و دیگری ابداع یک الگوریتم بسیار کارامد با نام
سیمپلکس برای حل گروهی از مسائل بهینهسازی توسط جرج دانتزیک در سال 1947. امروز OR شاخهای
از ریاضیات و مدیریت است که متخصصین آن در بنگاههای اقتصادی و تجاری و صنایع مختلف، نقش
مهمی دارند و تصمیمات آنها در افزایش سود، کاهش زیان، بالا بردن راندمان و کاهش ضایعات و
مسائلی از این دست، بسیار مؤثر است.
اینترنت و وب نیز داستان مشابهی دارند. در حقیقت، وب، مهمترین عاملی بود که به عمومیشدن
اینترنت کمک کرد و باعث شد افراد زیادی با آن آشنا شوند. در سال 1969 ارتش امریکا با اهداف
نظامی، از پروژهای با نام Internet رونمایی میکند که کامپیوترهایی را که در نقاط مختلف
دنیا قرار دارند، به هم متصل میکند و مطمئن میشود که این اتصال بهگونهای است که اگر در
شرایطی مانند یک حملهی اتمی، تعدادی از این کامپیوترها نابود شوند، سایر کامپیوترها
میتوانند به ارتباطشان ادامه دهند. بعد از چند سال، تعدادی از دانشگاهها و شرکتهای خصوصی
به استفاده از این تکنولوژی جدید روی میآورند اما به دلایلی مانند پیچیدگی زیرساخت
شبکههای کامپیوتری و هزینههای بالای راهاندازی آن، عمومیشدن این تکنولوژی تا سالها بعد
هم رخ نمیدهد. اما درست دو دهه بعد از تولد اینترنت، یعنی در سال 1989 یک سرویس مبتنی بر
اینترنت با نام World Wide Web که به اختصار Web نامیده میشد، توسط یک دانشمند انگلیسی با
نام Timothy Berners-Lee ارائه شد که با استقبال چشمگیری مواجه شد و عموم مردم را با این
سرویس و به تبع آن با ستون فقرات این سرویس یعنی اینترنت، آشنا کرد.
آقای Berners-Lee کار روی این سرویس را حدود یک دهه قبل از انتشار عمومی آن و با هدفی
متفاوت، شروع کرده بود. در اوایل دههی 1980 ایشان و همکارانشان در یک مرکز تحقیقاتی مربوط
به پژوهشهای هستهای در کشور سوئیس با نام اختصاری CERN، از یک سیستم اطلاعاتی با نام
Enquire رونمایی کردند که به کارکنان CERN امکان میداد که اسنادی را روی شبکهی این سازمان
به اشتراک بگذارند. در پیادهسازی این سیستم، از یک روش سازماندهی اسناد به نام اَبَرمتن
(Hypertext) برای اتصال اسناد به یکدیگر استفاده شده بود که به کارمندان امکان میداد با
کلیک روی یک لینک (hyperlink) از سندی به سند دیگر منتقل شوند. همچنین، از یک معماری
درخواستوپاسخ برای تبادل اسناد بین کارمندان استفاده میشد؛ یعنی یک کارمند، سند مورد نظر
خود را درخواست میکرد و هر کامپیوتری که از آن سند میزبانی میکرد، آن را برای کاربر
درخواستکننده نمایش میداد.
کارایی سیستم اطلاعاتی آقای Berners-Lee خیلی زود مشخص شد و او را به این فکر انداخت که
سیستمی مشابه آنچه روی شبکهی CERN ساخته بود، روی بزرگترین شبکهی دنیا یعنی اینترنت
پیادهسازی کند و بر همین اساس، پروپوزالی را به مدیران CERN ارائه داد. اما مرکز CERN حاضر
به تأمین مالی برای این پروژه نبود و بنابراین، آقای Berners-Lee و چند نفر از همکارانشان،
مستقلاً کار ساخت سرویس مورد نظرشان را که ابتدا Mesh و بعداً Web نامیده شد، شروع کردند.
تا سال 1989 همهی اجزای مورد نیاز سرویس Web توسط این تیم ساخته شد و در این سال، از این
سرویس اینترنتی رونمایی شد.
سایر سرویسهای اینترنت
بدون تردید، وب مهمترین سرویسی است که تاکنون بر بستر اینترنت ارائه شده و میزان
استفاده از این سرویس به حدی زیاد بوده که اغلب مردم، آن را با اینترنت یکی میدانند و
بعضاً واژههای وب و اینترنت را به جای هم به کار میبرند. اما واقعیت این است که وب
فقط یکی از سرویسهای متعدد و متنوعی است که روی اینترنت ارائه میشود و وقتی وب متولد
شد، حدود دو دهه از عمر اینترنت گذشته بود. برخی دیگر از سرویسهای پرکاربردی که روی
اینترنت ارائه میشوند، عبارتند از: پست الکترونیکی (email)، رسانههای اجتماعی
(social media)، تلفن اینترنتی (VOIP)، سرویسهای اتصال راه دور (remote connection)
مانند Telnet و SSH، سرویسهای برگزاری کنفرانسهای ویدیویی مانند Adobe Connect و
غیره. اینترنت برای همهی این سرویسها و تکنولوژیها حکم ستون فقرات (backbone) را
دارد.
سرویس وب در روزهای ابتدایی، به هیچوجه پیچیدگیهای وضعیت امروزی خود را نداشت و اسناد وب،
فقط شامل متن بودند. اما با گذر زمان و طی یک روند تکاملی، امکان افزودن انواع محتواهای
دیگر مانند تصاویر، فیلمها و انیمیشنها به اسناد وب ممکن شد و این سرویس به وضعیتی رسید
که امروز میبینیم. در ادامه، اجزای تشکیلدهندهی وب را معرفی میکنیم و خواهیم دید که
چطور رشد و تکامل این اجزا سبب تکامل سرویس وب شده است.
اجزای سازندهی وب
وب را میتوانیم از دو منظر، مورد بررسی قرار دهیم: یکی به عنوان یک سیستم اطلاعاتی
(Information System) یا IS و دیگری به عنوان یک سرویس اینترنتی. وب به عنوان یک سیستم
اطلاعاتی، مجموعهای است از اسناد که با استفاده از یک زبان نشانهگذاری (markup) به نام
HTML ایجاد میشوند و به عنوان یک سرویس اینترنتی، وب دارای یک پروتکل اختصاصی با نام HTTP
یا HyperText Transfer Protocol است که امکان تبادل اسناد را از طریق اینترنت فراهم میکند
و به لایهی Application از مدل OSI تعلق دارد. یادآوری میکنم که پیادهسازی پروتکلهای
لایهی Application بر عهدهی اپلیکیشنهای شبکه است. در مورد سرویس وب و پروتکل HTTP نیز
باید یک اپلیکیشن در سمت کاربر و یک اپلیکیشن در سمت سرور وجود داشته باشد که پروتکل HTTP
را پیادهسازی کرده و ارتباط بین دستگاهها را ممکن سازد. اپلیکیشنی که این کار را در سمت
کاربر انجام میدهد، مرورگر وب یا Web Browser نامیده میشود و در سمت سرور نیز یک اپلیکیشن
با نام HTTP Server این کار را انجام میدهد.
به طور کلی، چهار کامپوننت یا مؤلفهی کلیدی در ساخت سرویس وب نقش دارند که عبارتند از:
HTML: زبان ایجاد اسناد یا صفحات وب.
HTTP: پروتکل انتقال اسناد یا صفحات وب.
Web Browser: اپلیکیش سمت کاربر وب که علاوه بر ارسال
درخواستهای HTTP، کار تفسیر کدهای HTML سند دریافتی و نمایش آن برای کاربر را نیز
انجام میدهد.
HTTP Server: اپلیکیشن سمت سرور وب که درخواستها را دریافت
و پردازش کرده و پاسخ مناسب را برای هر درخواست ارسال میکند.
در ادامه، هر یک از این مؤلفهها را به صورت جداگانه و با جزئیات بیشتر بررسی میکنیم و
نگاهی نیز خواهیم داشت به تغییرات و بهبودهایی که این مؤلفهها در طول زمان به خود
دیدهاند.
زبان تولید اسناد وب: HTML
همانطور که گفته شد، وب، شامل مجموعهای از اسناد است و زبانی که برای ایجاد این اسناد به
کار میرود، HTML نام دارد که اختصاری است برای HyperText Markup Language. بنابراین، یک
سند وب، یک فایل متنی ساده به زبان HTML است که دارای پسوند .html است. HTML یک
زبان نشانهگذاری (markup) است و محتوای سند را با استفاده از برچسبزدن (tagging) به متن،
ایجاد میکند. برای مثال، متنی که برچسب یا تگ h1 را دریافت میکند، یک تیتر یا عنوان محسوب
میشود ولی اگر به همین متن تگ p نسبت داده شود، یک پاراگراف به حساب میآید. این زبان،
شامل مجموعهای از عناصر یا تگهای از پیش تعریفشده (pre-defined tags) است که هر یک برای
ایجاد نوع مشخصی از محتوا در اسناد وب، کاربرد دارند. هر مرورگر وب به یک موتور رندر HTML
مجهز است که تگهای HTML را میشناسد و بر این اساس، کار تفسیر کدهای HTML و نمایش سند را
انجام میدهد.
مستندات وب و W3C
هر استاندارد وب مانند HTML دارای یک سند رسمی موسوم به specification یا spec است که
حاوی تمام اطلاعات و جزئیات مربوط به آن استاندارد است. این مستندات حجم بسیار زیادی
دارند و برای اهداف آموزشی مناسب نیستند. در واقع، مخاطب اصلی این اسناد، سازندگان
مرورگرها و سایر نرمافزارهایی هستند که کار تفسیر و رندر صفحات وب را انجام میدهند.
در سل 1994 سازمانی به نام W3C یا World Wide Web Consortium به مدیریت آقای
Berners-Lee تأسیس شد که کار تدوین استانداردهای وب و از جمله HTML را بر عهده داشت.
اما پس از منازعات و کشمکشهای سیاسی که در ادامه به چند و چون آن اشاره خواهیم کرد،
تغییراتی به وجود آمد و در حال حاضر، گروهی به نام WHATWG متولی استاندارد HTML و مسئول
ارائهی مستندات این زبان است.
اولین نسخه از زبان HTML که در سال 1989 توسط آقای Berners-Lee و همکارانشان معرفی شد، خیلی
مختصر و جمعوجور بود و فقط شامل 18 عنصر بود؛ در واقع، اسناد وب در آن زمان، فقط شامل
«متن» بودند. اما در نسخههای بعدی HTML، عناصری به این زبان افزوده شد که امکان قرار دادن
تصاویر، جداول، فرمهای تعاملی وب، فیلمها، صداها و انیمیشنها در اسناد وب را فراهم
میکردند. اگر فرایند توسعهی HTML از سال 1989 تا امروز را مورد بررسی قرار دهیم،
میتوانیم این بازهی زمانی را به چهار زیربازهی اصلی تقسیم کنیم:
دورهی اول، از HTML1.0 تا HTML4.01(1989-1999): اولین نسخهی عمومی از HTML
با نام HTML1.0 در سال 1989 توسط آقای Berners-Lee معرفی شد. این نسخهی ابتدایی شامل
فقط 18 عنصر بود و «متن» تنها نوع محتوایی بود که با استفاده از این نسخه، قابل تولید
بود. سال 1995 نسخهی HTML2.0 معرفی شد که شامل عناصر بیشتری بود و امکان ایجاد جداول و
فرمها را نیز در اسناد وب فراهم میکرد. دو سال بعد، HTM3.2 با عناصر و امکانات بیشتر
منتشر شد و در سال 1999 نسخهی HTML4.01 به عنوان یکی از محبوبترین نسخههای این زبان،
منتشر شد و امکان قرار دادن انواع بیشتری از محتوا، بهویژه مالتیمدیا را در اسناد وب
فراهم کرد.
دورهی دوم، تولد و مرگ XHTML(1999-2009): نسخهی HTML4.01 امکانات زیادی
داشت و با استقبال خوبی از سوی توسعهدهندگان وب همراه شد اما مشکلی که در آن مقطع
زمانی وجود داشت، این بود که مرورگرها کار پیادهسازی مستندات HTML را به شکل یکسانی
انجام نمیدادند و این کارِ برنامهنویسان وب را مشکل میکرد. در حقیقت، اگرچه W3C
متولی استاندارد HTML بود، اما این سازمان دارای قدرت قهری نبود و مرورگرها کار
پیادهسازی مستندات تدوینشده توسط این سازمان را به شکل مورد نظر خودشان انجام
میدادند. سرانجام W3C برای کنترل اوضاع، دست به ریسک بزرگی زد و در سال سیاه 2000 از
یک نسخهی جدید و متفاوت با نام XHTML رونمایی کرد. XHTML یا eXtensible HyperText
Markup Language برخلاف HTML با سایر زبانهای نشانهگذاری و از جمله XML سازگار بود و
استاندارد سختگیرانهتری محسوب میشد. اما چرا این کار یک ریسک محسوب میشد؟ چون XHTML
یک مشکل را حل میکرد اما مشکل جدیدی به بار میآورد و معلوم نبود مرورگرها چه واکنشی
به این موضوع داشته باشند. XHTML به گرامر سفتوسخت XML متکی بود و این باعث میشد که
مشکل «تفاوت در پیادهسازی» حل شود اما از طرف دیگر، با HTML سازگار نبود (چون نه یک
توسعه از HTML، بلکه یک بازنویسی کامل از آن محسوب میشد) و بنابراین، مشکل جدیدی به
نام «عدم سازگاری با نسخههای قبلی» به بار میآورد. سازگاری با نسخههای قبلی
(backward compatibility) برای مرورگرها و توسعهدهندگان، موضوعی حیاتی محسوب میشد و
اگر مرورگرها XHTML را جایگزین HTML4.01 میکردند، برای نمایش وبسایتهایی که با
استفاده از HTML ایجاد شده بودند، دچار مشکل میشدند. W3C امیدوار بود که مرورگرها و
توسعهدهندگان حاضر شوند این مشکل را به عنوان بهای «رسیدن به یک استاندارد واحد با
پیادهسازی یکسان» بپذیرند و به آیندهی وب فکر کنند. اما وقتی XHTML2 در سال 2002
معرفی شد، W3C با طغیان مرورگرها و استنکاف از پذیرش آن مواجه شد. مرورگرها و
توسعهدهندگان وب در سال 2004 یک کارگروه اختصاصی با نام WHATWG یا Web Hypertext
Application Technology Working Group تشکیل دادند و به این کارگروه مأموریت دادند که
برای XHTML یک هماورد با نام HTML5 بتراشد. به هر حال، در سال 2009 با توقف توسعهی
XHTML، پیروز این رقابت مشخص شد و W3C با یک چشم اشک و دیگری خون، منشوری را برای
WHATWG تعیین کرد تا بر اساس آن، HTML5 را به عنوان استاندارد نسل بعدی توسعه دهد.
دورهی سوم، نسخهی انقلابی HTML5(2009-2019): پس از سالها کار و آزمایش بر
روی HTML5، این نسخه از زبان به طور رسمی در سال 2014 معرفی شد. HTML5 با نسخههای قبلی
سازگار بود اما در عین حال، با تغییرات و بهبودهای زیادی همراه بود. در این نسخه، روی
جنبهی معنایی (semantic) عناصر تأکید زیادی شده بود و کار با مالتیمدیا و قرار دادن
فیلم و صوت در اسناد وب، خیلی سادهتر شده بود. علاوه بر این، امکانات ویژهای مانند
اعتبارسنجی خودکار فرمهای وب نیز در این نسخه ارائه شد. امکانات این نسخه به گونهای
بود که حتی سیستمعاملهایی نیز با تکیه بر HTML5 ایجاد شد. برای نمونه، کمپانی کرهای
LG سیستمعاملی با نام WebOS معرفی کرد که در واقع یک توزیع لینوکسی است که اینترفیس آن
بر پایهی HTML5 و سایر تکنولوژیهای وب است. شرکتهای دیگری نظیر پاناسونیک و سونی نیز
دست به اقدام مشابهی زدند اما سیستم عاملهای آنها توان لازم برای رقابت با اندروید و
iOS را نداشتند و نتوانستند موفقیتی بهدست بیاورند.
دورهی چهارم، توسعهی HTML به عنوان یک Living Standard(2019+): بعد از
اینکه W3C پذیرفت که قید XHTML2 را بزند و WHATWG را به عنوان مسئول استاندارد HTML5
معرفی کرد، مستندات استاندارد HTML هم توسط WHATWG و هم توسط W3C نگهداری و توسعه داده
میشد. با وجود تلاشهایی که در راستای حفظ تشابه مستندات این دو گروه صورت میگرفت،
بعضاً اختلافاتی بین آنها دیده میشد که البته در بیشتر مواقع، قابل اغماض بود. اما
بعد از چند سال همکاری، W3C و WHATWG با یک اختلاف اساسی مواجه شدند. داستان این اختلاف
از این قرار بود که W3C مایل بود کمافیالسابق HTML را با یک رویکرد استاتیک توسعه دهد؛
یعنی روی ویژگیهای جدید کار کند و سپس، از همهی آن ویژگیها در قالب یک نسخهی جامع
جدید مانند HTML6 و HTML7 رونمایی کند. اما از طرف دیگر، WHATWG طرفدار یک رویکرد
دینامیک در توسعه و بهروزرسانی HTML بود که Living Standard نام دارد. در این روش،
استاندارد HTML میتواند هر لحظه با یک یا چند ویژگی جدید بروزرسانی شود و خبری از
نسخههای جامع نیست و در عوض، میتوان به طور دورهای از مستندات، اسنپشات (snapshot)
تهیه کرد. با وجود این اختلاف نظر اساسی، دو گروه که از مضرات وجود دو استاندارد مجزا
آگاه بودند، سعی کردند به همکاری خود ادامه دهند و لذا برای مدتی روال کار اینطور بود
که WHATWG توسعهی HTML را با نام HTML Living Standard انجام میداد و W3C با تهیهی
اسنپشات به طور دورهای، نه یک نسخه اما یک وضعیت جدید از HTML را معرفی میکرد و
لیستی از مشخصات مورد نظرش را نیز به آن میافزود. اما در ماه مِی سال 2019
تفاهمنامهای بین W3C و WHATWG به امضا رسید که بر اساس آن، نگهداری از استاندارد HTML
به صورت یک Living Standard به WHATWG سپرده شد و بنا شد که W3C انتشار لیستهای مستقل
مشخصات و ویژگیهای مربوط به HTML را متوقف کند و تسهیلاتی نیز برای همکاریهای مشارکتی
(و نه مستقل) W3C در تولید مستندات در نظر گرفته شد. بنابراین، توجه داشته باشید که
HTML استانداردی است که در هر لحظه امکان افزودهشدن یک ویژگی جدید به آن وجود دارد اما
به هر حال، ویژگیهای جدید، زمانی قابلیت استفاده پیدا میکنند که توسط مرورگرها
پیادهسازی و پشتیبانی شوند. ضمناً در اغلب موارد، باید مرورگرهای قدیمیتر را نیز در
نظر داشته باشید. در طول این آموزش، بهمرور با روشهایی برای اطمینان از نمایش صحیح
اسناد وب خود در مرورگرهای مختلف و بررسی وضعیت پشتیبانی مرورگرها از ویژگیهای HTML
آشنا میشوید.
پروتکل ارتباطی وب: HTTP
مؤلفهی دوم وب، HTTP یا HyperText Transfer Protocol است. وب به عنوان یک سرویس تحت شبکه،
به یک پروتکل ارتباطی برای تبیین قوانین مربوط به فرمت پیامها و انتقال اسناد بین
دستگاهها نیاز داشت و از همینرو در طی سال های 1989 تا 1991 پروتکلی با نام HTTP توسط
آقای Berners-Lee و همکارانشان توسعه داده شد. HTTP نیز در گذر زمان، دستخوش تغییرات
فراوانی شده و یک روند تکاملی را طی کرده است. با وجودی که همواره سعی شده تا توسعهی HTTP
به گونهای باشد که با حفظ سادگی و افزایش انعطافپذیری همراه باشد، اما بههرحال با بزرگ
شدن این پروتکل، افزایش پیچیدگی آن امری اجتنابناپذیر بوده است. در ادامه، خواهیم دید که
HTTP با گذراندن چه روندی، از یک پروتکل ساده برای تبادل فایلهای متنی در یک محیط
آزمایشگاهی و نیمهامن به یک پروتکل مفصل تبدیل شده که انتقال تصاویر، فیلمهای باکیفیت
(high resolution) و محتوای سهبعدی را بر اساس یک معماری درخواستوپاسخ، ممکن کرده است.
HTTP/0.9، پروتکل تکخطی: اولین نسخه از HTTP بینهایت ساده بود. درخواستها فقط از یک خط
تشکیل میشدند و هر درخواست با تنها متد موجود در آن نسخه یعنی Get شروع شده و با مسیر فایل
مورد نظر، تکمیل میشد. به همین ترتیب، هر پاسخ نیز بسیار ساده و تنها شامل فایل درخواستی
بود. در این نسخه، تنها فایلهای قابل انتقال، اسناد وب یا همان فایلهای HTML بودند و حتی
در صورت بروز خطا نیز یک فایل HTML تولید میشد که شامل توصیفی از مشکل رخداده بود. این
نسخه را بعدها HTTP/0.9 نامگذاری کردند تا آن را از نسخههای بعدی، متمایز کنند.
HTTP/1.0، پروتکل قابل بسط: نسخهی ابتدایی HTTP/0.9 بسیار ساده بود اما در طی سالهای
1991
تا 1995، خود مرورگرها و سرورها قابلیتهایی را به آن اضافه کردند. برای نمونه، با هر
درخواست، یک خط status code نیز به ابتدای پاسخها اضافه شد که باعث میشد که مرورگر از
موفقیتآمیز بودن یا نبودن درخواست، مطلع شود و بر اساس آن، رفتار مناسبی (مانند
بهروزرسانی یا استفاده از حافظهی موقت یا local cache) انجام دهد. اما از همهی اینها
مهمتر، مفهوم هدر (HTTP header) بود که امکان تبادل متادیتا را فراهم میکرد. برای نمونه،
یک هدر با نام Content-Type باعث شد که انواع دیگری از فایلها بهجز فایلهای HTML نیز
امکان انتقال در وب را پیدا کنند. هدرهای HTTP، موجب بسطپذیری (extensibility) این پروتکل
شدند، چون همیشه امکان اضافه کردن قابلیت جدیدی از طریق هدرها وجود دارد. در آن سالها
مرورگرها و سرورها، ویژگیهای جدید را با استفاده از یک رویکرد try-and-see به HTTP اضافه
میکردند؛ یعنی قابلیتی را اضافه میکردند و سپس، میدیدند که آیا کشش مناسب برای این
قابلیت وجود دارد یا خیر. سرانجام برای پایان دادن به این آشفتگیها، در اواخر سال 1996 یک
سند اطلاعاتی منتشر شد که برخی از ویژگیهای اضافی را که توسط مرورگرها و سرورها استفاده
میشد، تثبیت کرده و برخی دیگر را کنار گذاشته بود. این سند با نام HTTP/1.0 و با نام رسمی
RFC 1945 منتشر شد.
HTTP/1.1، پروتکل استاندارد: به موازات بسط HTTP/1.0 کار استانداردسازی HTTP نیز در حال
انجام بود و فقط چند ماه بعد از انتشار HTTP/1.0 و در ابتدای سال 1997 اولین نسخهی
استاندارد از این پروتکل با نام HTTP/1.1 منتشر شد. در این نسخه، چند ابهام برطرف شده و
بهبودهایی نیز دیده میشد. یکی از این بهبودها به امکان استفادهی مجدد و چندباره از یک
اتصال، مربوط میشد. به این ترتیب، دیگر برای نمایش آیتمهای تعبیهشده در یک سند، نیازی به
برقراری یک اتصال مجدد نبود و چنانچه در سندی منابعی وجود داشت که به درخواست مجزا نیاز
داشته باشند، اتصال برقرار میماند و درخواستهای مورد نیاز ارسال میشدند. همچنین، یک
قابلیت کلیدی به نام Pipelining نیز افزوده شد که باعث میشد یک درخواستِ دوم بتواند قبل از
دریافت نتیجهی کامل درخواست اول، ارسال شود و این به معنای کاهش تأخیر در ارتباطات بود.
مکانیزمهای جدیدی نیز برای کنترل cache معرفی شد و همچنین، قابلیتی به نام Content
negotiation که به مرورگر و سرور امکان میداد که قبل از ارسال، بر سر مواردی مانند زبان و
encoding و نوع محتوایی که باید ارسال شود، توافق کنند. بسطپذیری HTTP، افزودن هدرها و
متدهای جدید به آن را ساده کرده بود. در سال های 1999 و 2014 دو بازبینی اصلاحی روی
HTTP/1.1 صورت گرفت.
HTTP/2، پروتکل بهینه: با گذر زمان و افزوده شدن به قابلیتهای HTML و امکان استایلدهی
اسناد وب با استفاده از CSS و اسکریپتنویسی با استفاده از زبانهایی مانند جاوااسکریپت،
اسناد وب پیچیدهتر شدند و برخی از آنها بیشتر از اینکه یک سند باشند، نوعی اپلیکیشن محسوب
میشدند. در چنین شرایطی و با افزایش حجم دادههای انتقالی در وب، کارایی (performance) به
یک موضوع کلیدی برای HTTP تبدیل شد. در سال 2010 گوگل یک پروتکل آزمایشی به نام SPDY را
معرفی کرد که با حفظ مفاهیم پایهای مانند هدرها و متدها و status code، تغییراتی را در
نحوهی فرمتبندی و ترانسفر دادهها بین کلاینت و سرور انجام داده بود که تأثیر چشمگیری روی
کاهش سرعت بارگذاری اسناد وب داشت. گروه کاری HTTP با مبنا قرار دادن SPDY کار بر روی
نسخهی بعدی HTTP را شروع کردند و بهخاطر تفاوتهای بنیادین آن با HTTP1.1، آن را نه
HTTP1.2 بلکه HTTP/2 نامیدند. برای مدتی، SPDY و HTTP/2 به موازات همدیگر توسعه داده
میشدند و روال کار به این صورت بود که ویژگیهای مورد نظر ابتدا روی SPDY آزمایش شده و
سپس، در HTTP/2 پیادهسازی میشد. در HTTP/2 فرم کاملی از multiplexing که به موازیسازی
ارسال درخواستها مربوط میشد، پیادهسازی شد و با تقسیم یک پیام به فریمهای باینری و
فشردهسازی هدرهای هر فریم، تأخیر در بارگذاری اسناد به شکل قابلتوجهی کاهش یافته بود. به
علاوه، امکان اولویتبندی درخواستها (requests prioritization) و اعلام میزان اهمیت منابع
درخواستی به سرور، فراهم شده بود و ویژگی جدیدی به نام Server Push باعث میشد که سرور بعد
از دریافت درخواست بارگذاری یک سند، یه جای اینکه منتظر درخواستهای بعدی برای سایر منابع و
آیتمهای مورد نیاز آن سند باشد، آن منابع را نیز برای کلاینت ارسال کند. همهی اینها از
طریق افزودن یک لایهی جدید به نام framing layer پیادهسازی شده بود و مفاهیم اصلی و
پایهای مانند هدرها و متدها به قوت خود باقی بودند. به هر حال، HTTP/2 به لحاظ کارایی نسبت
به HTTP/1.1 وضعیت خیلی بهتری دارد و مطابق آمار ارائهشده، تا ماه جولای سال 2022 حدود
46.7% از وبسایتها از این پروتکل استفاده میکنند.
HTTP/3، پروتکلی برای آینده: HTTP/3 که از آن با نام پروتکل نسل بعدی وب یاد میشود، باز
هم
با سردمداری گوگل توسعه داده میشود. HTTP/3 در لایهی Transport بهجای TCP از یک پروتکل
مبتنی بر UDP با نام QUIC استفاده میکند و باز هم بیش از هرچیز، کارایی یا performance را
هدف قرار داده و ترانسفر منابع در وب را سرعت میبخشد. در حقیقت، HTTP/3 یک مشکل مهم در
HTTP/2 با نام head-of-line-blocking را حل میکند. داستان این مشکل به طور خلاصه از این
قرار است که: مکانیزم موازیسازی یا multiplexing در HTTP/2 بهگونهای است که در صورت بروز
مشکل برای یک بسته، تمام تراکنشهای فعال بدون توجه به اینکه تحت تأثیر بستهی گم شده قرار
دارند یا خیر، متوقف میشوند. اما آنچه که QUIC ارائه میدهد یک موازیسازی بومی (native
multiplexing) است که باعث میشود گمشدن یک بسته، تنها روی تراکنشهای مربوط به آن بسته
تأثیر بگذارد.
اپلیکیشن سمت کاربر وب: Web Browser
سومین مؤلفهای که سرویس وب را شکل میدهد، مرورگر وب (web browser) است؛ اپلیکیشنی که دو
نقش عمده در وب دارد: یکی ارسال درخواستهای HTTP برای سرور و دیگری تفسیر کدهای سند
دریافتی و نمایش آن برای کاربر. اولین مرورگر وب با نام WorldWideWeb توسط آقای Berners-Lee
ساخته شد و البته نسبت به مرورگرهای امروزی موجود بسیار سادهای بود. اما افزایش قابلیتهای
وب و توسعهی زبان HTML و امکان استایلدهی به اسناد وب با استفاده از CSS و نیز امکان
اسکریپتنویسی در صفحات وب با استفاده از زبانهایی مانند جاوااسکریپت، باعث پیچیدگی
روزافزون مرورگرهای وب شده است. یک مرورگر وب امروزی، تنها مختص وب نیست و پروتکلهای دیگری
نظیر FTP، SSH و Telnet را نیز پیادهسازی کرده است.
جنگ مرورگرها
تاریخ جهان مملو است از نبردهای ویرانگر بر سر تصاحب قدرت، سوداهای بی حد و مرز برای
تسخیر جهان و تلاشهای قهرمانانه و حماسهوار برای اصلاح اوضاع یا شاید تغییر در
جغرافیای قدرت. تاریخ مرورگرهای وب نیز از این قاعده مستثنی نیست و به عنوان یک مشت
نمونهی خروار، تاریخ جهان را در ابعادی کوچکتر روایت میکند. سال 1993 سال انفجار وب
بود. در این سال، مرورگری با نام Mosaic به عنوان اولین مرورگر گرافیکی جهان منتشر شد.
سازندهی این مرورگر یعنی آقای Marc Andreessen یک سال بعد، شرکتی با نام Netscape را
تأسیس کرد و مرورگر Navigator را برای عموم منتشر کرد. بلافاصله بعد از آن، غول
نرمافزاری دنیا یعنی Microsoft مرورگری را ایجاد کرد و آن را Internet Explorer یا IE
نامید. با انتشار این مرورگر توسط مایکروسافت، یک جنگ تمامعیار بین این کمپانی و
Netscape درگرفت و هر یک از این دو شرکت سعی داشت با ارائهی ویژگیهای جالبتر و
جذابتر، کاربران را به استفاده از مرورگر خودش ترغیب کند. به عنوان بخشی از این
تلاشها، Netscape یک زبان اسکریپتنویسی با نام غیررسمی JavaScript ایجاد کرد و با
پیادهسازی مفسر این زبان در مرورگر Navigator، امکاناتی را برای وبسایتها به بار آورد
که آنها را از صفحاتی استاتیک به صفحات دینامیک و تعاملپذیر تبدیل میکرد و در عوض،
مایکروسافت با معرفی CSS استاندارد جدیدی را برای استایلدهی و تعیین ظاهر صفحات وب
تولید کرد. اما برگ برندهی مایکروسافت در این مبارزه، سیستمعامل ویندوز بود. با
ارائهی IE به عنوان مرورگر پیشفرض سیستمعامل ویندوز، مایکروسافت تا سال 1999 توانست
95% از سهم بازار را به مرورگر خود اختصاص دهد. Netscape که بهشدت در این جنگ شکست
خورده بود و از نعمتی مثل سیستمعامل بیبهره بود، سعی کرد زمین و قواعد بازی را تغییر
دهد و یک دعوای حقوقی ضد انحصار (antitrust) علیه مایکروسافت مطرح کرد. برای اینکه ژست
قهرمانانه و انحصارستیز Netscape باورپذیرتر شود، این شرکت مرورگر خود را به صورت
متنباز (open source) منتشر کرد و در سال 2002 یک مؤسسهی غیرانتفاعی به نام Mozilla
تأسیس کرد و نام مرورگر خود را به Firefox تغییر داد. تا سال 2010 مرورگر Firefox و
سایر رقبایی که در این سالها به میدان رقابت وارد شده بودند، توانستند سهم IE را به
50% کاهش دهند. در این بین، مرورگر Google Chrome شروع به پیشیگرفتن از رقبای خود کرد
و در حال حاضر (اواخر سال 2023) نزدیک به دو سوم از بازار مرورگرهای وب را در اختیار
دارد. مایکروسافت هم در سال 2015 از مرورگر جدید خود یعنی Edge در سیستمعامل جدید
ویندوز 10 رونمایی کرد و این روزها یک نسخهی جذاب از این مرورگر را در ویندوز 11 ارائه
داده است. در ابتدا به نظر میرسید که برنامهی مایکروسافت، جایگزینی کامل Edge با IE
است اما بعداً مشخص شد که رویکرد مایکروسافت این است که هر دو مرورگر را در ویندوز 10
ارائه دهد تا Edge به عنون یک مرورگر مدرن برای نمایش وبسایتهای امروزی مورد استفاده
قرار گیرد و IE نقش یک legacy browser را داشته باشد که برای نمایش وبسایتهای قدیمیتر
کاربرد دارد. سرانجام در ویندوز 11، مایکروسافت IE را حذف کرد و در عوض، قابلیتی به نام
IE Mode را در مرورگر Edge پیادهسازی کرده تا کاربران برای مشاهدهی وبسایتهای قدیمی
از آن استفاده کنند. رقابت بین مرورگرها هرگز به پایان نخواهد رسید و همین الان هم در
جریان است و در این بین، هر مرورگری با استراتژی خودش پا به میدان میگذارد. شرکتهایی
مانند مایکروسافت و اپل که از نعمتی به نام سیستمعامل برخوردارند، مرورگرهای خود را به
عنوان گزینهی پیشفرض در سیستمعامل خود ارائه میدهند و هر روز تغییر مرورگر پیشفرض
را برای کاربران، سختتر میکنند. اما مرورگرهایی مانند Firefox و Opera شعارهای ضد
انحصارطلبی سر میدهند و به دنبال حمایت جامعهی متنباز (open source community)
هستند. علاوه بر این، روند توسعهی مرورگرها به گونهای است که ظاهراً باید آنها را نسل
بعدی سیستمعاملها بدانیم.
گاهی از عبارت user agent نیز برای اشاره به یک مرورگر وب استفاده میشود. به طور کلی، user
agent به اپلیکیشنی گفته میشود که در سمت کاربر، کاری را از جانب او انجام میدهند.
صفحهخوانها (screen readers) که کدهای HTML یک سند یا صفحهی وب را تفسیر کرده و بهجای
نمایش بصری صفحه، محتوای آن را برای کاربر میخوانند، نوع دیگری از اپلیکیشنهای user agent
هستند.
اپلیکیشن سمت سرور وب: HTTP Server
چهارمین و آخرین مؤلفهی ساختاری وب HTTP Server نام دارد که web server نیز نامیده میشود و
همانطور که از نامش برمیآید، نقش سرور را در سرویس وب بازی میکند. در واقع، وب به عنوان
سرویسی که از معماری client-server برخوردار است، در سمت سرور، به اپلیکیشنی نیاز دارد که
بتواند درخواستهای HTTP را دریافت و پردازش کند و نتیجه را به عنوان پاسخ، ارسال کند. بر
خلاف مرورگر وب که به سادگی نصب شده و قابلیت استفاده پیدا میکند، نصب و راهاندازی یک
HTTP Server به پیکربندیهای خاصی نیاز دارد. Apache و Nginx دو مورد
از شناختهشدهترین و
محبوبترین اپلیکیشنهای HTTP Server هستند که بیشترین سهم بازار را به خود اختصاص
دادهاند. البته روزبهروز به محبوبیت LiteSpeed نیز افزوده میشود و ناگفته نماند که IIS
نیز نام HTTP Server اختصاصی مایکروسافت است.
وب چطور کار میکند؟
وقتی کاربری قصد مشاهدهی یک سند یا صفحهی وب را داشته باشد، آدرس آن صفحه را در نوار آدرس
مرورگر وارد میکند یا روی یک لینک کلیک میکند و مرورگر، صفحهی مورد نظر را برای او نمایش
میدهد. در این بخش، قصد داریم ببینیم در پشت پردهی این فرایند، چه اتفاقاتی رخ میدهد.
البته آنچه در اینجا مطرح میشود، یک حالت سادهشده از اتفاقات متعدد و پیچیدهای است که رخ
میدهد. قبل از هر چیز، باید با مفاهیم DNS و URL آشنا شویم و ببینیم منظور از میزبانی وب
(Web Hosting) چیست.
DNS چیست؟
یادآوری میکنم که هر کامپیوتر در شبکه دارای یک آدرس ip است که سایر کامپیوترها از آن آدرس
برای برقراری ارتباط با آن کامپیوتر استفاده میکنند. به خاطر سپردن آدرسهای ip برای انسان
ساده نیست اما خوشبختانه متناظر با هر آدرس ip، یک نام دامنه (Domain Name) وجود دارد که
میتوان به جای ip از آن استفاده کرد. قطعاً بهخاطر سپردن عبارتی مانند google از عبارتی
مثل 27.158.142.18 خیلی سادهتر است.
هر نام دامنه از یک یا چند برچسب (label) و یک TLD یا Top-Level Domain تشکیل شده که پسوند
دامنه نیز گفته میشود. به عنوان مثال، در نام دامنهی google.com عبارت google یک برچسب
محسوب میشود و .com پسوند دامنه یا TLD است. برچسب یا label در یک نام دامنه میتواند هر
عبارتی شامل یک حرف یا حتی یک جملهی کامل باشد. در ضمن، یک نام دامنه میتواند از بیش از
یک برچسب تشکیل شده باشد که در این صورت، برچسبها باید با نقطه (dot) از هم جدا شوند.
مجوز استفاده از یک نام دامنه
امکان خرید یک نام دامنه وجود ندارد و تنها میتوان با پرداخت حق استفاده از یک نام
دامنه برای یک یا چند سال از آن استفاده کرد. برای دریافت حق استفاده از یک نام دامنه،
باید از خدمات شرکتهایی موسوم به ثبتکننده یا Registrar استفاده کرد. این شرکتها
سرویسی موسوم به who is را ارائه میدهند که با استفاده از آن میتوان از آزاد بودن یا
نبودن یک نام دامنه اطلاع پیدا کرد و در صورت آزاد بودن نام دامنهی مورد نظر، حق
استفاده از آن را برای مدت مشخصی ثبت کرد. با پایان مدت استفاده از نام دامنه، آن نام
دامنه مجدداً آزاد میشود. البته پس از اتمام مدت استفاده از یک نام دامنه، همیشه
اولویت تمدید با مالک قبلی است و تنها در صورتی که آن فرد یا سازمان نخواهد آن را تمدید
کند، دامنه برای دیگران قابل استفاده خواهد شد. برای استفاده از پسوندهای دامنهی عمومی
مانند .com یا .net یا .org نیاز به اخذ مجوز خاصی نیست اما برای برخی از
پسوندها باید
مجوزهای لازم را دریافت کرد. به عنوان مثال، .gov تنها برای سازمانهای دولتی قابل
استفاده است و یا پسوندهای محلی مانند .ir به کسب مجوز از دولتها نیاز دارند. در ضمن،
برای بعضی نامهای دامنه فقط یک ثبتکننده وجود دارد. مثلاً .fire پسوندی است که در
انحصار کمپانی آمازون قرار دارد.
حالا سؤال اینجاست که مرورگر چطور آدرس ip متناظر با یک نام دامنه را پیدا میکند؟ پاسخ این
سؤال، سیستم نام دامنه (Domain Name System) یا DNS است. DNS به بیان ساده یک دیتابیس
غیرمتمرکز است که مثل یک دفترچهی تلفن، مقابل هر ip نام دامنهی متناظر آن ip را نوشته
است. این دیتابیس غیرمتمرکز توسط سرورهایی به نام DNS Server در دسترس قرار میگیرند و
مرورگر بعد از دریافت نام دامنه، با اتصال به یک سرور DNS آدرس ip آن دامنه را پیدا میکند
و به مرورگر تحویل میدهد. البته، اگر بخواهیم دقیقتر باشیم، باید بگوییم که اتصال به یک
سرور DNS، آخرین کاری است که مرورگر انجام میدهد و قبل از آن، سعی میکند از روی حافظهی
کش مرورگر یا سیستمعامل، آدرس ip دامنه را پیدا کند. وقتی مرورگر، آدرس ip مربوط به
دامنهی مورد نظر را پیدا کند، آدرس کامپیوتر مقصد را در اختیار دارد و در ادامه، یک
درخواست HTTP مناسب تولید کرده و برای کامپیوتر مقصد که میزبان فایل درخواستی کاربر است،
ارسال میکند.
البته سیستم DNS یکی از پیچیدهترین سیستمهای مربوط به اینترنت و شبکه است و از یک ساختار
سلسلهمراتبی بهره میبرد که پرداختن به جزئیان آن به یک آموزش مفصل و جداگانه نیاز دارد.
URL چیست؟
همانطور که دیدیم، یک ip یا نام دامنه، آدرس یک کامپیوتر در شبکه است. ولی چیزی که در نوار
آدرس مرورگر وارد میشود، یک ip نیست، بلکه یک URL است که ip یا نام دامنه نیز بخشی از آن
است. در حقیقت، ما یک فایل یا منبع (resource) را درخواست میکنیم نه یک کامپیوتر را. URL
یا Uniform Resource Locator آدرس یک منبع در اینترنت است. یک منبع میتواند یک سند وب، یک
استایلشیت، یک عکس، فیلم یا هر فایل دیگری باشد که در وب پشتیبانی میشود. به URL نمونهی
زیر نگاه کنید.
قسمت اول URL، مشخصکنندهی پروتکلی است که مرورگر باید استفاده کند. یادآوری میکنم که
مرورگرها پروتکلهای متعددی را پیادهسازی کردهاند و بنابراین، قبل از هر چیز باید تعیین
کنیم که قصد استفاده از چه پروتکلی را داریم. پروتکل وب، HTTP است که البته یک نسخهی
امنتر با نام HTTPS نیز دارد.
قسمت بعدی، مشخصکنندهی نام دامنه است که همانطور که گفته شد، کامپیوتر مقصد را مشخص
میکند. طبیعتاً به جای نام دامنه میتوان از آدرس ip نیز استفاده کرد.
در قسمت بعد، شمارهی پورت پروسه یا اپلیکیشن مقصد (که در مورد سرویس وب، یک HTTP Server
است) بعد از یک کاراکتر دونقطه (colon) آورده میشود. در حالت پیشفرض، یک HTTP Server از
پروتکل HTTP روی پورت 80 و از HTTPS روی پورت 443 میزبانی میکند. اگر این تنظیمات پیشفرضِ
وبسرور تغییر داده نشده باشند، نیازی به ذکر شمارهی پورت نیست.
قسمت بعدی یک URL به آدرس مسیر منبع مورد نظر در کامپیوتر مقصد، مربوط است. اگر این بخش در
یک URL وجود نداشته باشد، مطابق تنظیمات وبسرور، درخواست برای فایل پیشفرضی که صفحهی
اصلی یک وبسایت یا یک دایرکتوری است، فرستاده میشود.
قسمت بعدی نیز شامل پارامترهای اضافی فراهمشده برای سرور است. این پارامترها لیستی از
جفتهای کلید و مقدار هستند که با کاراکتر & از هم جدا میشوند.
میزبانی وب چیست؟
یک وبسایت مجموعهی از صفحات وب است که از یک نام دامنهی مشترک استفاده میکنند. انتشار یک
وبسایت به معنای قرار دادن صفحت آن وبسایت روی یک کامپیوتر سرور است که با اجرای دائمی یک
اپلیکیشن HTTP Server به یک سرور وب تبدیل شده است. یک کامپیوتر سرور وب باید دائماً روشن
باشد و به اینترنت متصل بوده و اپلیکیشنهایی مانند HTTP Server در آن مدام در حال اجرا
باشند. بدیهی است که چنین کامپیوتری به سخت افزار قدرتمند و تجهیزات جانبی فراوانی نیاز
دارد. علاوه بر اینها، با توجه به کار زیادی که توسط یک کامپیوتر سرور وب انجام میشود،
باید در شرایط دمایی و محیطی مناسبی نگهداری شود. به همهی اینها مواردی مثل تأمین امنیت
سرور را نیز اضافه کنید. بنابراین، داشتن یک کامپیوتر سرور وب، چندان راحت نیست.
بنابراین، اکثر افراد و شرکتهای کوچکتر که شرایط تهیه و نگهداری سرور را ندارند، از خدمات
شرکتهای ارائهدهندهی خدمات میزبانی وب (Web Hosting) استفاده میکنند. این شرکتها از
کامپیوترهای سرور متعدد خود در مراکزی موسوم به Data Center نگهداری میکنند و به دارندگان
وبسایتها پیشنهاد میکنند که در ازای دریافت مبلغی، از سایت آنها روی سرورهای خودشان
میزبانی کنند.
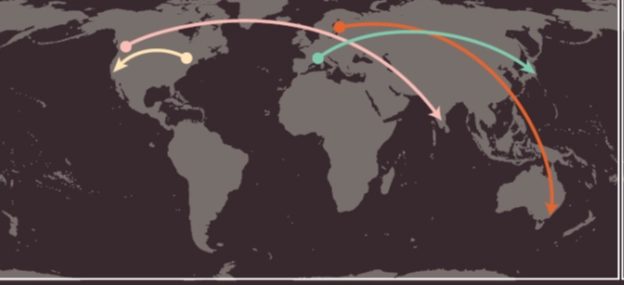
این تصویر از کتاب HTML & CSS نوشتهی John Dockett آورده شده است.
در تصویر بالا نقاط ابتدایی هر پیکان، مکان یک کاربر فرضی را نشان میدهد که در حال مشاهدهی
یک وبسایت است و نقطهی انتهایی هر پیکان به محل سرور میزبان وبسایت اشاره میکند. به عنوان
مثال، فلش سبز رنگ کاربری را نشان میدهد که از بارسلون اسپانیا درخواست مشاهده وبسایت
sony.jp را از طریق یک مرورگر وب ارسال کرده است. سپس، DNS دستبهکار شده و ip مربوط به
نام دامنه sony.jp را پیدا کرده و متوجه میشود که مکان کامپیوتر میزبان این وبسایت در
توکیو است.
پشت پردهی وب
بسیار خوب، حالا میتوانیم فرایند پشت پردهی ارسال درخواست و نمایش نتیجه توسط مرورگر برای
کاربران وب را درک کنیم. یک کاربر آدرس URL مربوط به سند مورد نظرش را در نوارد آدرس یک
مرورگر وارد میکند. مرورگر قبل از هر چیز، یا از طریق حافظهی کش خود یا سیستمعامل و یا
از طریق اتصال به یک سرور DNS، آدرس ip متناظر با نام دامنهی موجود در URL را پیدا میکند
و سپس، یک درخواست HTTP مناسب تولید کرده و برای کامپیوتر سروری که از سند مورد نظر میزبانی
میکند، ارسال میکند. درخواست ارسال شده در سمت سرور توسط یک HTTP Server دریافت شده و در
صورت نیاز پردازشهای لازم در سمت سرور انجام شده و سند مورد درخواست کاربر به همراه سایر
منابع وابسته به آن سند، برای مرورگر فرستاده میشود. سپس، مرورگر با دریافت پاسخ و تفسیر
کدهای موجود در سند، محتوی آن سند را برای کاربر نمایش میدهد.